

On-demand Testing
On-Demand testing comes into action when there is an unexpected project or sudden change in delivery.Providing a cost-effective solution for short-term QA needs.

CrowdSourced Testing
Elevate the digital experience of your customers using the power of crowdsourced testing Deliver higher-quality mobile, cloud, and website apps.
Our key services

Automation Testing
Increase testability and simplify release management with an efficient automation testing approach.

Security Testing
Validate security across all layers of the software, detect vulnerabilities and loopholes with an adequate security testing approach.

Performance Testing
Enhance Your Software’s Functionality, Reach More Audience, Get Rated Well, And Grow Your Sales With Our Dynamic Performance Testing Services.
Platforms We Cover In Testing

Web Services
Struggling with responsive design, broken locators, or flaky tests? Look no ahead. TestUnity’s mature web testing practice makes web automation easy (as it should be). TestProject unleashes Selenium to build the most robust web testing solution available.

Web App
Powerful automated testing for any web application. Responsive web, react, angular, and more. TestUnity has your web application testing covered.

Android App
Robust testing for qa testing any Android application. Native apps, hybrids apps, and more. TestUnity can test any Android Devices and helps you easily handle your sea of Android devices.

IOS App
Save time and money with iOS app testing that adjusts to your requirements. Our tailored testing methods and comprehensive plans allow us to make you look amazing mobile app testing.

AR/VR
With trained testers, TestUnity delivers unparalleled AR/VR testing expertise in a multitude of cultures and languages. Our creative, technical talent explores your device like your customers would in real devices and a real environment software testing tools but writes issue reports catered to developers’ requirements.

Wearables
The success of a wearable is dependent on its functionality, reliable experience, secure operations, and seamless coexistence with different computing technologies. TestUnity offers thorough quality checks on these varied parameters ensuring the apps work flawlessly and are ready for real-world consumption.

Database
Ensure the database's efficiency, highest stability, performance, and security by utilizing TestUnity’s Database testing methods. We also assess data integrity and consistency, which might incorporate building tough queries to load and stress test the database and check its responsiveness.

IoT Devices
Our IoT Device Testing Services are created to deliver manufacturers’ guidance and support through each stage of product development. Our one-stop-shop portfolio is integrated with our industry-specific experience tailored to meet your individual requirements for testing.
Tools We Use For Testing

































Envision 01
We first clearly understand your needs and assess your testing maturity level.
Exhaustive Reporting 04
We perform Exhaustive Reporting to keep you updated about the current status of the project and the quality of the product.
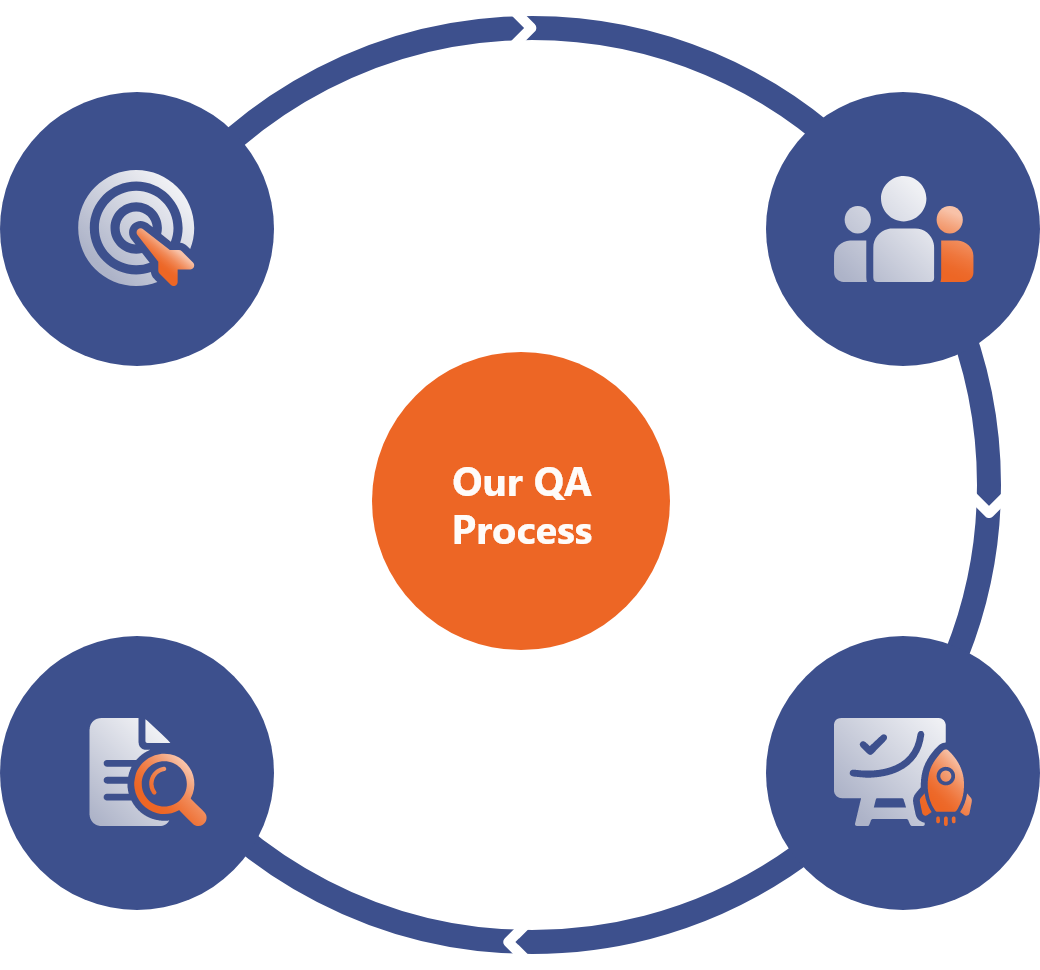
Allocation of Team 02
We select the best bunch of QAs according to your testing needs.
Project Kick Off & Execution 03
We finalize the Testing method and start the execution of the project.
Our Engagement Models
Managed Testing Services
Benefit from TestUnity’s specialized testing abilities with a partnership for managed QA services. We take care of the complete QA essentials, including staffing, delivery, program management, and thought leadership.
- Outcome-based services as per the service levels with low effort on governance
- Allows you to focus on your core business


Project- Based Testing
Project-based testing engagement with agreed deliverables or resources to help satisfy your project requirements
- Meet project milestones with the certainty of high product quality
- Fixed Cost or T&M based on scope and project plan clarity
Dedicated Team
Create Your Perfect Team with Any combination of team members, from QA Manager to general tester.
- Use as an external QA department or augment your internal one
- Completely scalable at any timesoftware testing company


Managed Crowd Testing
TestUnity’s managed app testing formula combines professional services, a global network of pro-level testers, and best-in-class software testing. Find the show-stopper problems that matter the most.
- 24/7 access to our network of the best-trained, most motivated testers in the business
- Fast, flexible and on-demand
Our Case Studies

Functional Testing of Little Millennium Web App
Little Millennium is a renowned preschool that ignites young minds with boundless curiosity and a passion for learning. With a legacy of excellence in early education, Little Millennium offers a holistic approach that integrates the best of play-based learning, creativity, and academic readiness. Their dedicated team of educators is committed to providing personalized attention to […]

Functional Testing
Functional Testing of Physica(ComXr) Application
ComXR is a technology company that creates memorable experiences for your audience by leveraging virtual reality (VR). We specialize in high-end VR, one that allows your users to physically walk through and naturally interact with a truly lifelike, fully 3D environment. With a focus on quality, creativity, and technical expertise, we deliver customized solutions that […]

Security Testing
Security Testing of Bloom AI Application
Bloom AI is on a mission to operationalize data to fuel business ingenuity in the digital economy. As business-data partners, we turn complex, siloed data into simple, digestible insights using our proprietary microinsights platform and headless business intelligence solutions. As companies scale their modern data infrastructure, Bloom AI helps users take the next step by […]

Functional Testing
Functional Testing of Travel Tech Website
Travel Tech is a completely virtual and free event, which offers tourism trade professionals (tourism, destinations, travels, and hospitality) educational resources and actionable strategies that will help them move toward recovery and improve profitability more quickly. In this case, the problem was that client was not sure from where to start, how to start, what […]

Automation Testing
Regression Testing of Contestee Platform
In English, “Contestee” refers to someone competing in a contest. Contestee is a social network that promotes global talent discovery through competitions. Using Contestee, anyone can showcase their amazing talents, skills, and attributes. Become famous by uploading your videos, collecting votes, and collecting likes! TestUnity began working on Contestee in November 2019. An Android and […]

Security Testing
Security Testing of NFT Platform
NgageN is an exclusive platform enabling NFT economies between Brands & Creators. Created byone of the leading Blockchain companies in India, NgageN is an invitation-only platform for credibleBrands & Creators to drive new forms of fan engagement, sources of revenue & community buildingby creating NFTs which provide exclusive digital assets as well as experiences. In […]
Industries We Serve

Banking & Finance

Aerospace & Defence

Gaming

Government

Healthcare

Insurance

Legal

Media & Entertainment

Education

Retail

Telecom

Travel & Hospitality
Our client's word
 FIFO life Australia
FIFO life Australia
I was really happy with the service mate, and your availability.Didn't matter whether day or night you were there if I needed you. Really appreciated that.And I know there were a lot of bugs that your team found that I had no idea were there.
Qdesk
We have been very impressed with the flexibility & dedication that Testunity has shown towards our assignment.The communication between both the teams was very good. They helped us avoid any errors and delays and made the working experience memorable.
Whizkidz media
You guys are awesome, just align device details to your report for better reading.
 Gifft
Gifft
TestUnity came to our defense with their team of talented and professional Cybersecurity experts and their full package of Cyber Security engineering services and solutions. Their team not only did a splendid job close our last minutes requirments but also went above and beyond to support us to make sure we meet third party timelines. They ensured positive engagement and successful partnership throughout the project with their communication , timeliness, and skills.We would recommend TestUnity as a trusted partnership
Sunil Karani
Head of Professional Services
 Asheh Consulting
Asheh Consulting
Ranjan and his excellent team of test consultants have been a great extension to our Testing Ecosystem. Highly Professional and Motivated. Happy how TestUnity served, pricing plan was within our budget. Flexible resourcing and accommodative planning and support . Open to Feedback. Ranjan has been outstanding as a vendor partner.
Anu
Asheh Consulting, Founder/ALM Architect
 ComXR
ComXR
We had a great experience with TestUnity for testing our app. They had a very thorough and professional approach to testing which were aligned in processes and best practices. Would highly recommend.
Rehan Poonawala
Founder - ComXR
FIFO life Australia
I was really happy with the service mate, and your availability.Didn't matter whether day or night you were there if I needed you. Really appreciated that.And I know there were a lot of bugs that your team found that I had no idea were there.
Qdesk
We have been very impressed with the flexibility & dedication that Testunity has shown towards our assignment.The communication between both the teams was very good. They helped us avoid any errors and delays and made the working experience memorable.
Whizkidz media
You guys are awesome, just align device details to your report for better reading.
FIFO life Australia
I was really happy with the service mate, and your availability.Didn't matter whether day or night you were there if I needed you. Really appreciated that.And I know there were a lot of bugs that your team found that I had no idea were there.
Qdesk
We have been very impressed with the flexibility & dedication that Testunity has shown towards our assignment.The communication between both the teams was very good. They helped us avoid any errors and delays and made the working experience memorable.
Whizkidz media
You guys are awesome, just align device details to your report for better reading.
Get In Touch
Connect with us directly
Our credentials

